
Comment fonctionne un modèle de langage IA ?


L’intelligence artificielle fait désormais partie du quotidien : assistants de rédaction, chatbots, moteurs de recherche augmentés, résumés automatiques… Pourtant, très peu de personnes savent réellement comment fonctionne un modèle de langage.
Comprendre ces mécanismes n’est pas un détail technique : c’est ce qui permet de mieux utiliser l’IA, de formuler des demandes plus efficaces, d’éviter les hallucinations et de savoir quand une réponse doit être vérifiée.
Dans son rapport Digital 2026, publié par DataReportal, il est souligné que plus d’un milliard de personnes utilisent chaque mois des outils d’IA autonomes. Autrement dit, nous interagissons massivement avec des systèmes dont nous comprenons rarement le fonctionnement interne. Pour autant, il n’est pas nécessaire d’être ingénieur pour saisir les grandes idées.
L’objectif est de comprendre comment une IA lit un texte, comment elle est entraînée, pourquoi elle répond si bien à certaines questions et moins bien à d’autres, et comment les technologies comme le RAG et le “chunking” permettent de fiabiliser ses réponses.
I. Comment une IA comprend un texte ?
Avant d’expliquer comment l’IA apprend, il faut d’abord comprendre comment elle représente le langage. Contrairement à un humain, elle ne lit pas des phrases dans leur forme classique. Elle transforme tout en nombres, analyse ces nombres avec des mathématiques, et prédit ensuite la suite la plus probable.
1. Les phrases sont découpées en petits morceaux (appelés “tokens”)
Les modèles de langage ne lisent pas “Paris est une belle ville”. Ils découpent la phrase en petits fragments, un peu comme un puzzle :
« Paris », « est », « une », « belle », « ville ».
Ce principe est expliqué dans la documentation Tokenization d’OpenAI, qui montre que les IA traitent le texte non pas comme du langage naturel, mais comme une série de “morceaux numériques”. C’est la première étape : rendre le texte compatible avec des calculs mathématiques.
Exemple simple :
Pensez à un GPS. Le mot “Paris” devient une coordonnée numérique.
L’IA fonctionne exactement comme ça : des mots → des nombres.
2. Chaque morceau est transformé en vecteur numérique (un “embedding”)
Une fois découpés, les tokens sont convertis en vecteurs, c’est-à-dire en suites de nombres. Ces vecteurs permettent au modèle de représenter le sens de manière géométrique :
- deux mots proches en sens → vecteurs proches (par exemple “chien” et “animal”),
- deux mots très différents → vecteurs éloignés (“chien” et “politique”).
3. L’IA analyse les relations entre les mots grâce à l’attention (“self-attention”)
C'est l'innovation de la self-attention qui a permis la création des modèles GPT, Claude, Mistral, Llama, etc.
L’idée est simple :
L’IA regarde tous les mots en même temps et décide lesquels sont importants pour comprendre le sens global.
Exemple :
« Marie a posé son sac. Elle est partie. »
Pour comprendre “elle”, l’IA doit repérer que le référent probable est “Marie”.
C’est exactement le rôle de l’attention.
Avec ce mécanisme, le modèle crée une sorte de carte mentale des relations entre les mots, des dépendances logiques, des références et du contexte.
4. Elle prédit le mot suivant, encore et encore
L’EPFL explique que les grands modèles de langage comme GPT‑4 reposent sur un principe simple mais efficace : « ils prédisent le mot suivant d’une phrase en fonction des mots précédents », ce qui constitue le cœur de leur fonctionnement.
Exemple simple :
« Le café est très ___ » → l’IA calcule la probabilité de milliers de continuations possibles (“chaud”, “bon”, “cher”…).
Ce mécanisme paraît très simple… mais répété des milliards de fois pendant l’entraînement, il permet au modèle :
- de résumer un texte,
- de répondre à des questions,
- d’expliquer un concept,
- de raisonner sur plusieurs étapes,
- ou même d’écrire du code.
C’est ce qui surprend souvent : une tâche très simple (prédire le prochain mot) peut produire des comportements très sophistiqués lorsqu’elle est appliquée à des quantités colossales de données.
II. Comment un modèle de langage est entraîné… et pourquoi il est meilleur dans certains domaines que dans d’autres
Pour comprendre pourquoi une IA semble “intelligente”, il faut regarder comment elle apprend et pourquoi elle réagit différemment selon les sujets. L’entraînement d’un modèle n’a rien à voir avec ce que ferait un humain : il ne cherche pas à comprendre la signification profonde d’un texte. Il apprend plutôt en jouant un jeu très simple… mais répété à une échelle gigantesque.
1. Un modèle entraîné sur des milliards de données (auto-supervision)
Le cœur de l’apprentissage repose sur une tâche unique : prédire le prochain mot.
C’est ce qu’on appelle l’apprentissage auto-supervisé.
Le modèle ne comprend pas le monde comme un humain, mais il apprend les régularités du langage, les structures, les associations fréquentes et les liens logiques.
Dans le rapport LLaMA 2 (Meta, 2023), les chercheurs expliquent que la performance d’un modèle dépend directement :
- de la quantité des données vues,
- et de leur diversité.
Cela explique pourquoi :
- un modèle est excellent en programmation s’il a lu des millions de lignes de code ;
- il est bon en histoire générale s’il a vu beaucoup de textes éducatifs ;
- il est limité dans un domaine très pointu si ce domaine est peu représenté dans les données.
Exemple concret : Si un modèle a lu énormément d’articles sur la cuisine mais très peu sur le droit administratif, il sera meilleur pour écrire une recette de lasagnes que pour interpréter une loi.
Le modèle devient donc très fort dans ce qu’il a beaucoup vu, et moins fiable dans les domaines rares ou spécialisés.
2. Les humains corrigent et guident le comportement (RLHF)
Une fois que le modèle sait prédire des mots, il faut encore lui apprendre à :
- répondre clairement,
- être poli,
- éviter les propos dangereux ou inappropriés,
- suivre des instructions.
Pour cela, les entreprises utilisent le RLHF : Reinforcement Learning from Human Feedback, expliqué dans le rapport RLHF (OpenAI, 2022).
Des humains évaluent plusieurs réponses proposées par le modèle, et une seconde IA apprend à imiter celles qui sont jugées meilleures.
C’est ce qui transforme un modèle brut en un assistant conversationnel capable de suivre des demandes comme “résume”, “explique”, “compare”, “traduis”…
3. Pourquoi les performances varient d’un domaine à l’autre ?
Comme le souligne LLaMA 2 (Meta, 2023), un modèle devient naturellement meilleur dans les domaines qu’il a beaucoup vus durant son entraînement. Il n’a donc pas de “compétences innées” : il reflète statistiquement ses données.
Certaines entreprises choisissent d’ailleurs d’orienter l’entraînement vers un usage précis (analyse de texte long, raisonnement, rapidité en français, créativité…), ce qui explique pourquoi chaque modèle excelle dans des tâches différentes et qu’il n’existe pas “une meilleure IA absolue”.
Les modèles peuvent être spécialisés par entraînement
Certaines entreprises entraînent des modèles orientés pour des tâches précises :
- Anthropic optimise Claude pour lire des textes longs avec précision.
- OpenAI optimise GPT-4 pour le raisonnement complexe.
- Mistral optimise certains modèles pour la vitesse et le français.
- Meta optimise LLaMA 3 pour la polyvalence et la créativité.
On peut donc avoir :
- un modèle très bon en code,
- un autre spécialisé en résumés,
- un autre pour les langues
- un autre pour l’analyse juridique.
Il n’existe pas une meilleure IA absolue, seulement une IA adaptée selon la tâche.
4. Pourquoi une IA “hallucine” quand elle manque d’informations
Dans une étude, les chercheurs d’Anthropic expliquent que les hallucinations apparaissent lorsque :
- le modèle manque de données fiables sur un sujet,
- ou lorsqu’il ne comprend pas totalement la question.
Comme un modèle doit toujours fournir une réponse, il produit quelque chose de plausible… mais faux.
Exemple :
Demande-lui un événement qui aura lieu en 2030 : elle peut inventer une réponse car elle ne possède pas l’information.
C’est une conséquence naturelle du fonctionnement probabiliste.
5. Le RAG permet de corriger une grande partie des hallucinations
Dans le rapport Retrieval-Augmented Generation publié par Meta AI en 2020, les chercheurs montrent que le RAG (qui consiste à rechercher dans des documents réels avant de répondre) réduit fortement les hallucinations.
Exemple simple :
Sans RAG → “Quel est le taux de TVA de ce contrat ?” → l’IA invente.
Avec RAG → l’IA lit le contrat → réponse correcte.
C’est la méthode la plus efficace actuellement pour rendre une IA fiable dans un cadre professionnel.
Pour en apprendre plus sur le RAG, nous invitons à aller lire notre article sur le sujet : “Qu’est-ce que le RAG (génération augmentée de récupération) ?”
III. Comment une IA “cherche” sur Internet ou dans vos documents ? (RAG, chunking, browsing)
Une confusion très fréquente consiste à croire que les modèles d’IA “se connectent” naturellement à Internet. En réalité, un modèle de langage pur ne navigue pas sur le web. Il ne sait rien de ce qui s’est passé après sa date d’entraînement. S’il répond à des questions d’actualité ou cite une page web, c’est grâce à un outil externe.
Cette distinction est importante pour comprendre comment fonctionnent les IA.
1. Le modèle ne va pas sur Internet : c’est l’outil autour qui cherche
Dans sa documentation Using Tools, OpenAI explique clairement que le modèle (GPT, Claude, Gemini, etc.) n’a pas accès au web par défaut.
Ce sont des modules externes, souvent appelés “tools” ou “plugins”, qui effectuent la recherche.
Fonctionnement simple :
- Tu poses une question : “Trouve-moi les dernières actualités sur l’inflation.”
- L’IA décide : “J’ai besoin d’un navigateur.”
- Le navigateur externe cherche l’information.
- Il donne les résultats à l’IA.
- L’IA lit les pages, puis génère une réponse.
C’est exactement ce que font des systèmes comme Perplexity : une combinaison entre un moteur de recherche et un modèle de langage.
2. Pourquoi découper vos documents ? Le “chunking” expliqué simplement
Les modèles d’IA ne peuvent pas lire un PDF entier d’un coup.
Leur mémoire a une taille limitée (appelée “fenêtre de contexte”).
Solution :
On découpe le document en petites parties appelées chunks.
Chaque chunk représente un petit extrait cohérent : un paragraphe, une section, une page.
Dans de nombreux guides techniques, on explique que des chunks :
- trop longs → l’IA rate l’essentiel,
- trop courts → elle perd le sens.
Exemple :
Un PDF de 100 pages → 300 chunks de 300–500 mots.
Quand tu poses une question :
→ le système retrouve les 3 ou 4 chunks les plus pertinents,
→ il les donne au modèle,
→ l’IA lit uniquement ces passages et répond.
C’est rapide, précis et bien plus fiable.
3. Quelle IA faut-il choisir pour votre entreprise ?
Il n’existe pas « la meilleure IA ». Les évaluations publiques (Chatbot Arena, HumanEval, 2024-2025…) montrent que chaque modèle est très bon dans certains cas… et moins bon dans d’autres.
ChatGPT reste le plus utilisé car il est populaire et fiable, mais d’autres modèles surpassent GPT sur la vitesse, le français, la logique ou les usages internes.
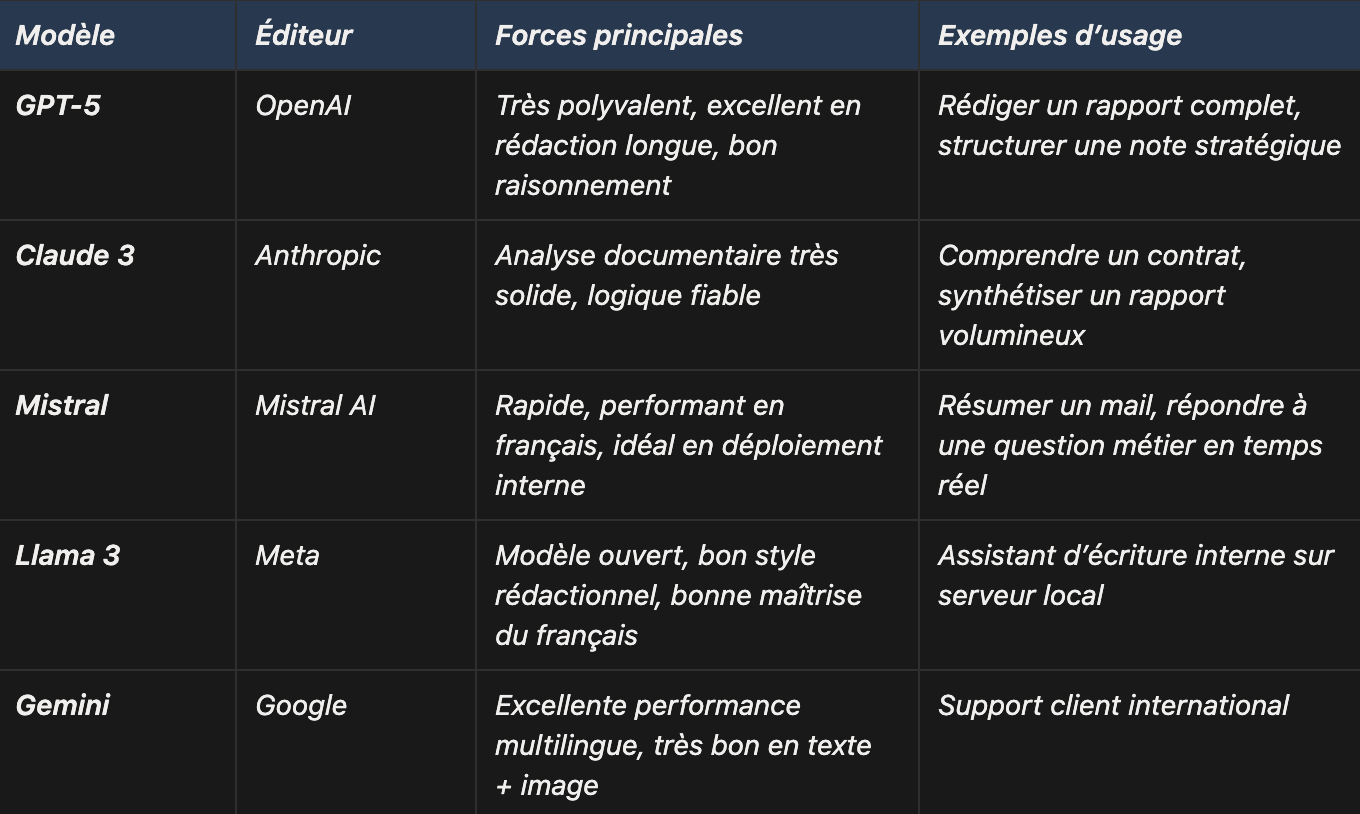
Selon la tâche, on ne choisirait pas le même modèle : un moteur rapide pour résumer, un moteur logique pour analyser, un moteur créatif pour rédiger, un moteur souverain pour traiter des données sensibles.
Il n’existe donc aucune IA qui coche toutes les cases.
4. L’orchestration de modèles
Plutôt que de choisir un seul modèle, certaines plateformes comme Delos font l’inverse : la plateforme analyse votre demande et sélectionne automatiquement le moteur le plus performant pour la tâche (GPT, Mistral, Claude, Llama…).
Vous obtenez donc la meilleure réponse possible, sans vous soucier des différences entre modèles.nn j
Par-dessus cette orchestration, Delos apporte :
- un hébergement souverain en France, avec chiffrement.
- un cloisonnement strict des accès (pas de mémoire, pas d’entraînement, permissions RLS).
- des applications spécialisées (Docs, Scribe, Réunion, Mail…).
Résultat : pour le même coût qu’un modèle unique, vous accédez à tous les modèles, à la meilleure performance pour chaque tâche, et dans un cadre sécurisé et souverain.
Conclusion : comprendre l’IA, c’est mieux l’utiliser
Comprendre comment fonctionne une IA n’est pas réservé aux ingénieurs. C’est au contraire une compétence essentielle pour tous ceux qui l’utilisent ou veulent l’utiliser au quotidien. Une IA n’est pas magique. Elle prédit des mots en fonction des données qu’elle a vues, et elle répond en cherchant la continuation la plus logique, pas la vérité absolue.
Dans son rapport Digital 2026, DataReportal souligne que plus d’un milliard de personnes utilisent chaque mois des outils d’IA. Pourtant, la grande majorité ignore que ces modèles ne lisent pas une page web comme un humain, qu’ils ne réfléchissent pas réellement, et qu’ils n’ont pas accès à Internet sans outil externe. Ils dépendent de leur entraînement, de leurs données et de leur capacité à analyser un contexte qui reste limité.
C’est cette réalité qui explique à la fois leur puissance et leurs limites :
- puissants lorsqu’ils ont été exposés à beaucoup d’exemples,
- brillants lorsqu’ils disposent d’un contexte clair,
- moins fiables lorsqu’ils manquent d’informations,
- vulnérables aux hallucinations lorsqu’ils doivent “deviner”.
C’est aussi pour cette raison que des technologies comme le RAG sont devenues indispensables. Et puisque chaque modèle excelle dans un domaine différent, certains pour rédiger, d’autres pour analyser, d’autres encore pour résumer ou coder, il devient logique de ne plus se limiter à une seule IA.
C’est exactement le rôle d’une plateforme multi-modèles comme Delos : orchestrer les modèles les plus performants, appliquer du RAG pour fiabiliser les réponses, utiliser vos documents internes, et sélectionner automatiquement l’IA la mieux adaptée à la tâche.
.jpeg)



Prêt à démarrer avec Delos ?
Commencez dès maintenant avec 7 jours offerts ou demandez un accompagnement personnalisé.
