
How does an AI language model (LLM) work?


Artificial intelligence is now part of everyday life: editorial assistants, chatbots, augmented search engines, automatic summaries... However, very few people really know How does a language model work.
Understanding these mechanisms is not a technical detail: it is what makes it possible to Make better use of AI, to formulate more effective requests, dTo avoid hallucinations and to know when a response needs to be checked.
In his report Digital 2026, published by DataRePortal, it is emphasized that more than 1 billion people use autonomous AI tools every month. In other words, we interact massively with systems whose inner workings we rarely understand. However, you don't have to be an engineer to grasp big ideas.
The objective is to understand how an AI reads text, how it is trained, why it answers some questions so well and others less well, and how technologies such as RAG and “chunking” make it possible to make its answers more reliable.
I. How does an AI understand text?
Before explaining how AI learns, we must first understand how it learns. represents the language. Unlike a human, she does not read sentences in their classical form. She turns everything into numbers, analyzes these numbers with mathematics, and then predicts the most likely outcome.
1. Phrases are broken up into small pieces (called “tokens”)
Language models don't read “Paris is a beautiful city.” They cut the sentence into small fragments, much like a puzzle:
“Paris”, “is”, “one”, “beautiful”, “city”.
This principle is explained in the documentation Tokenization From OpenAI, which shows that AIs treat text not as natural language, but as a series of “digital pieces.” This is the first step: making the text compatible with mathematical calculations.
Simple example:
Think of a GPS. The word “Paris” becomes a numerical coordinate.
AI works exactly like that: words → numbers.
2. Each piece is transformed into a digital vector (an “embedding”)
Once cut, the tokens are converted into vectors, that is to say into sequences of numbers. These vectors allow the model to represent the senses geometrically:
- two words that are close in meaning → nearby vectors (for example “dog” and “animal”),
- two very different words → distant vectors (“dog” and “political”).
3. AI analyzes relationships between words through attention (“self-attention”)
It is the innovation of the Self-attention which allowed the creation of the GPT models, Claude, Claude, Mistral, Llama, etc.
The idea is simple:
The AI looks at all the words at the same time and decide which ones are important for understanding the overall meaning.
Example:
“Marie put her bag down. She is gone.”
To understand “she”, the AI must identify that the probable referent is “Marie”.
That is exactly the role of attention.
With this mechanism, the model creates a kind of mental map of relationships between words, logical dependencies, references, and context.
4. She predicts the next word over and over again
EPFL explains that major language models like GPT‑4 are based on a simple but effective principle: “they predict the next word in a sentence based on previous words,” which is the core of how they work.
Simple example:
“Coffee is very ___” → the AI calculates the probability of thousands of possible continuations (“hot”, “good”, “expensive”...).
This mechanism seems very simple... but repeated Billions of times during training, it allows the model to:
- to summarize a text,
- to answer questions,
- to explain a concept,
- to reason over several stages,
- or even to write code.
This is what is often surprising: a very simple task (predicting the next word) can produce very sophisticated behaviors when applied to colossal amounts of data.
II. How a language model is trained... and why it's better in some areas than others
To understand why an AI seems “intelligent”, you have to look at how it learns and why it reacts differently depending on the subject. Training a model has nothing to do with what a human would do: it does not seek to understand the deeper meaning of a text. Instead, he learns by playing a very simple game... but repeated on a gigantic scale.
1. A model trained on billions of data (self-supervision)
The core of learning is based on a single task: Predict the next word.
It's called apprenticeship self-supervised.
The model doesn't understand the world like a human, but it does learn the language patterns, structures, frequent associations, and logical relationships.
In the report LLama 2 (Meta, 2023), the researchers explain that the performance of a model depends directly on:
- ofthe quantity data seen,
- And of their diversity.
This explains why:
- a model is excellent at programming if it has read millions of lines of code;
- he is good at general history if he has seen a lot of educational texts;
- it is limited in a very specific field if this area is poorly represented in the data.
Concrete example: If a model has read a lot of articles about cooking but very few about administrative law, he will be better at writing a lasagna recipe than at interpreting a law.
So the model becomes Very strong in what he saw a lot, and less reliable in rare or specialized fields.
2. Humans correct and guide behavior (RLHF)
Once the model can predict words, it still needs to be taught to:
- answer clearly,
- be polite,
- avoid dangerous or inappropriate language
- follow instructions.
For this, businesses use the RLHF: Reinforcement Learning from Human Feedback, explained in the report RLHF (OpenAI, 2022).
Humans evaluate several responses offered by the model, and a second AI learns to imitate the ones that are considered better.
That's what turns a raw model into a Conversational assistant able to follow up on requests like “summarize”, “explain”, “compare”, “translate”...
3. Why does performance vary from field to field?
As pointed out LLama 2 (Meta, 2023), a model naturally becomes better in the areas he saw a lot during his training. Therefore, he does not have “innate skills”: he statistically reflects his data.
Some companies also choose to focus training on specific use (long text analysis, reasoning, speed in French, creativity, etc.), which explains why each model excels at different tasks and that there is no “absolute best AI”.
Models can be specialized by drive
Some businesses train models that are oriented to specific tasks:
- Anthropic optimizes Claude to read long texts accurately.
- OpenAI optimizes GPT-4 for complex reasoning
- Mistral optimizes some models for speed and French.
- Meta optimizes LLama 3 for versatility and creativity.
So we can have:
- a very good code model,
- another specialized in summaries,
- Another one for languages
- another for legal analysis.
It does not exist an absolute better AI, only an AI adapted to the task.
4. Why does an AI “hallucinate” when it lacks information
In a study, researchers fromAnthropic explain that hallucinations occur when:
- The model lack of reliable data on a subject,
- or when he does not fully understand the question.
Because a model should always provide an answer, it produces something plausible... but wrong.
Example:
Ask her about an event that will take place in 2030: she can invent an answer because she does not have the information.
It is a natural consequence of functioning probabilistic.
5. The RAG can correct a large part of hallucinations
In the report Retrieval-Augmented Generation published by Meta AI in 2020, researchers show that RAG (which involves searching through real documents before responding) greatly reduces hallucinations.
Simple example:
Without RAG → “What is the VAT rate for this contract?” → AI is inventing.
With RAG → the AI reads the contract → correct answer.
It is the most effective method currently to make an AI reliable in a professional setting.
To learn more about RAG, we invite you to read our article on the subject: “What is RAG (enhanced recovery generation)?”
III. How does an AI “search” on the Internet or in your documents? (RAG, chunking, browsing)
A very common confusion is the belief that AI models naturally “connect” to the Internet. In reality, a language model unadulterated don't browse the web. He doesn't know anything about what happened after his training date. If he answers current questions or cites a web page, it is thanks to a external tool.
This distinction is important for understanding how AIs work.
1. The model does not go on the Internet: it is the tool around who is looking for
In its documentation Using Tools, OpenAI clearly explains that the model (GPT, Claude, Gemini, etc.) did not have no access to the web by default.
External modules, often called “tools” or “plugins”, perform the search.
Simple operation:
- You ask a question: “Find me the latest inflation news.”
- The AI decides: “I need a browser.”
- The external browser looks for the information.
- It gives the results to the AI.
- The AI reads the pages and then generates a response.
That's exactly what systems like Perplexity do: a combination of a search engine and a language model.
2. Why cut up your documents? “Chunking” explained simply
AI models can't read an entire PDF all at once.
Their memory has a limited size (called a “context window”).
Solution:
The document is divided into small parts called Chunks.
Each chunk represents a small coherent snippet: a paragraph, a section, a page.
In many technical guides, it is explained that chunks:
- too long → the AI is missing the point,
- too short → it loses meaning.
Example:
A 100-page PDF → 300 chunks of 300—500 words.
When you ask a question:
→ the system finds the 3 or 4 most relevant chunks,
→ he gives them to the model,
→ the AI only reads these passages and answers.
It's fast, accurate, and much more reliable.
3. Which AI should you choose for your business?
There is no such thing as “the best AI.” Public evaluations (Chatbot Arena, HumanEval, 2024-2025...) show that each model is very good in some cases... and not so good in others.
ChatGPT remains the most used because it is popular and reliable, but other models surpass GPT on speed, French, logic, or internal uses.
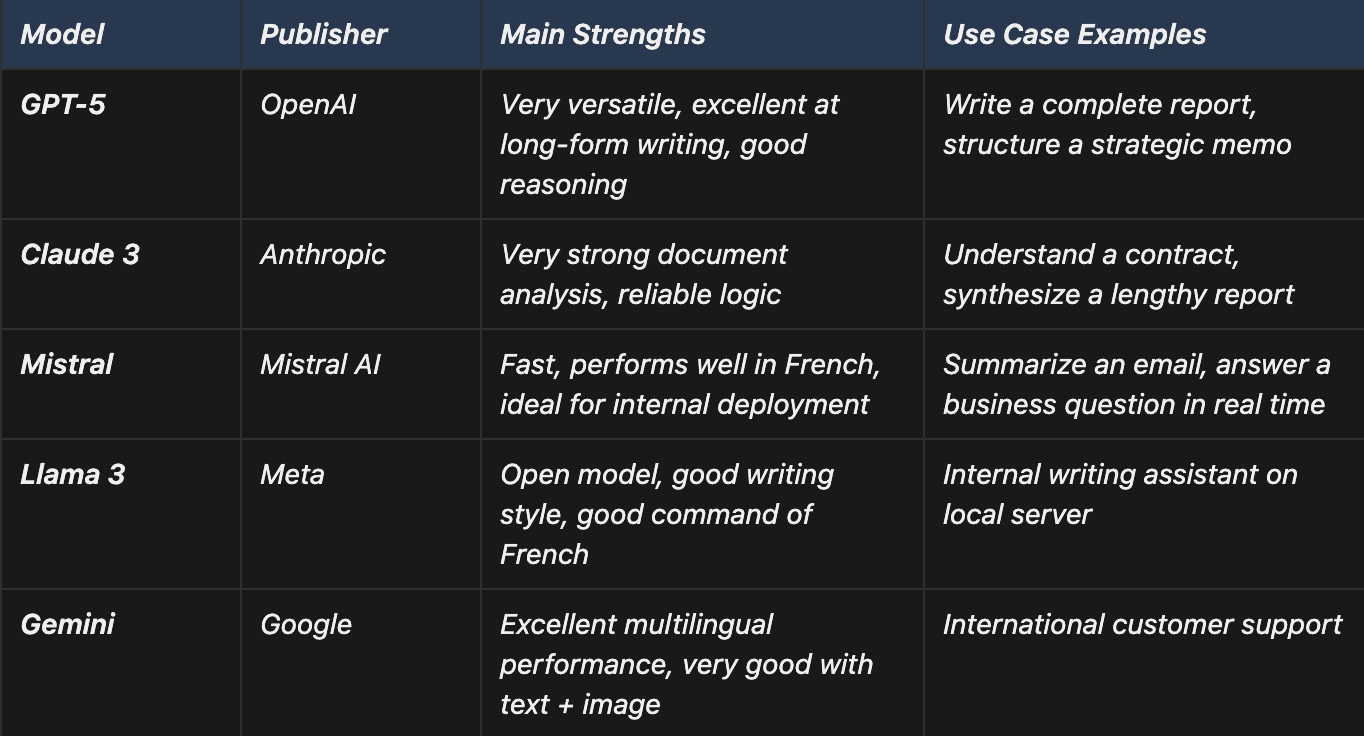
Depending on the task, we would not choose the same model : a fast engine to summarize, a logical engine to analyze, a creative engine to write, a sovereign engine to process sensitive data.
So it does not exist no AI that checks all the boxes.
4. Model orchestration
Instead of choosing only one model, some platforms like Delos do the opposite: the platform analyzes your request and automatically selects the best performing engine for the task (GPT, Mistral, Claude, Llama...).
So you get the best possible response, without worrying about differences between modes.Thes.nn J
On top of this orchestration, Delos brings:
- one sovereign accommodation in France, with encryption.
- one strict partitioning of accesses (no memory, no training, RLS permissions).
- Of specialized applications (Docs, Scribe, Meeting, Mail...).
Result: for the same cost as a single model, you have access to all models, at the best performance for each task, and within a framework secure and sovereign.
Conclusion: understanding AI means using it better
Understanding how AI works isn't just for engineers. On the contrary, it is an essential skill for anyone who uses it or wants to use it on a daily basis. An AI is not magic. She predicts words based on the data she saw, and she responds by looking for the most logical continuation, not the absolute truth.
In his report Digital 2026, DataRePortal points out that more than 1 billion people use AI tools every month. However, the vast majority are unaware that these models do not read a web page like a human, that they do not really think, and that they do not have access to the Internet without an external tool. They depend on their training, their data and their ability to analyze a context that is still limited.
It is this reality that explains both their power and their limits:
- powerful when exposed to lots of examples,
- brilliant when they have a clear context,
- less reliable when there is a lack of information,
- vulnerable to hallucinations when they have to “guess.”
It is also for this reason that technologies like the RAG have become indispensable. And since each model excels in a different field, some to write, others to analyze, others to summarize or code, it makes sense to no longer limit yourself to a single AI.
This is exactly the role of a multi-model platform like Delos : orchestrate the most efficient models, apply RAG to make responses more reliable, use your internal documents, and automatically select the AI best suited to the task.
.jpeg)



Ready to start with Delos?
Start now with a 7-day free trial or ask for personalized support.
