
What is RAG (Retrieval-Augmented Generation)?


THEGenerative AI has established itself in businesses to write emails, summarize meetings, respond to customers or help with the eve. Large language models (LLM) like GPT, Mistral or Llama know how to produce fluid and often relevant answers... but they have a major flaw: they can “hallucinate”, that is, inventing information that does not exist.
As an article by Oracle, LLMs are trained once and for all on vast generic corpora, with data that is sometimes outdated and rarely specific to a given company. Result: they don't know your contracts, your internal procedures, or your most recent products.
The enhanced recovery generation, or RAG (Retrieval-Augmented Generation), answers precisely this problem. It allows AI to consult your internal documents in real time before responding, rather than relying solely on what she learned during her training. The challenge is simple: to transform a brilliant but general AI into an assistant who really knows your business.
1. How does generative AI work (and why does it hallucinate)
A great language model works on a simple principle: it Predict the most likely next word based on the previous words. During his training, he is exposed to billions of sentences, learns language patterns, general facts about the world, and text structures (emails, reports, articles, etc.). Once trained, he knows how to write coherent content, summarize documents, explain concepts or rephrase messages.
The problem for a company is that its knowledge is Frozen at the time of training. It doesn't know your new offerings, updated internal policies, or contracts signed last year if they weren't in the original data. By default, an LLM doesn't see your PDFs, databases, or business systems.
And above all, when he doesn't know, he doesn't answer “I don't know.” He Continue to predict plausible words, which sometimes give very convincing answers... but wrong. It is this phenomenon that is called hallucinations.
Example:
An employee asks, “What are the training rights in our company agreement? ” If AI has never seen this agreement, it will respond by relying on common law or generic examples, without specifying that it is not specific to your business.
Faced with this, two main ways exist: retrain or adjust the model on your data (which is cumbersome), or let the model consult your documents at the time of the question. It is this second path that the RAG is implementing.
2. Retraining the model vs RAG
One could imagine solving the problem of hallucinations by retraining regularly the template on company documents. In theory, the more he sees your data, the more he integrates it. In practice, it's costly in terms of time, infrastructure, and skills. Each significant update imposes a new work cycle, and between two trainings, knowledge remains frozen.
Retraining is like asking a student to learn By heart the whole program, all appendices and updates prior to the exam. With each change, he must revise his entire course. The RAG, on the other hand, is like an “open book” exam: the student keeps his reasoning skills, but he is allowed to come up with a well-organized filing cabinet and to open it during the test. He doesn't know everything by heart, but he does Where to look the right information.
The RAG applies this logic to generative AI. The model maintains its general intelligence, its ability to write and summarize, but it is also given a controlled access to your internal documents and a search method to find relevant passages before answering. The article by Oracle summarizes this approach well: RAG makes it possible to optimize the responses of an LLM with targeted, more recent and company-specific information, without changing the model itself.
3. Simple definition of RAG
RAG (Retrieval-Augmented Generation) refers to a family of techniques that combine two blocks:
- A block of retrieving information, responsible for quickly finding in your documents the most relevant passages for a given question.
- A block of generation, usually an LLM, which then formulates the answer in natural language from these passages.
In practice, this means that AI no longer only relies on what it “has in its head”. She starts by looking for extracts from your contracts, procedures, or manuals, and then she uses these snippets to structure her response.
Example: Instead of asking the standard model to explain a customer contract signed in 2023, it is given access to this contract at the time of the question. He reads the relevant clauses and then writes a summary adapted to the request.
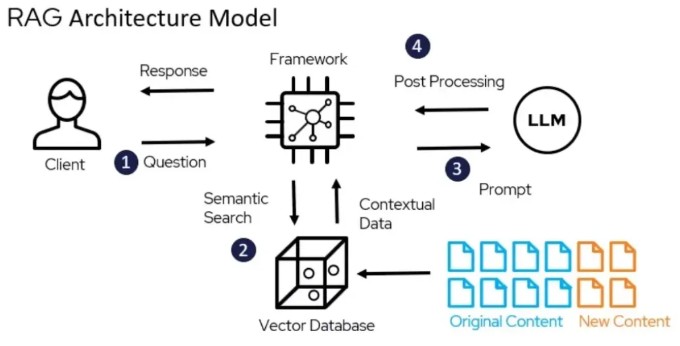
4. How does a RAG system work, in concrete terms?
It all starts with the construction of a knowledgebase. The company gathers useful documents: contracts, terms and conditions, technical documentation, technical documentation, technical documentation, internal procedures, reports, FAQ, etc. These documents are standardized in a usable format (often text or PDF), then divided into smaller pieces: paragraphs, sections, extracts. These segments are stored in a documentary database.
Next comes a key step: the vectorization. Each piece of text is transformed into a kind ofdigital footprint that summarizes its meaning. These fingerprints are stored in a vector database, designed so that the AI can quickly find the closest passages of a question, even if the words used are not exactly the same. Actors like Oracle or microsoft emphasize the central role of these bases in modern RAG systems.
When the user asks a question, for example: “What are the withdrawal periods provided for in our B2B general terms and conditions of sale? ”, the system searches this database for the most relevant extracts (an article of the GTC, an amendment, a legal note) and sends them to the language model, which then writes a clear answer based on these elements.
An important advantage of the RAG is the traceability. Since each extract is linked to a specific document, the system can indicate where the information comes from: file name, date, section, page. Oracle points out that this ability to go back to the source makes it possible, in case of error, to correct the right document rather than looking blindly.
Example:
The answer shows: “Withdrawal period of 14 calendar days (CGV 2024, article 4.2).” Just below, the interface shows the exact passage of the PDF, highlighted. The collaborator can check the original text in one second.
5. Concrete use cases of RAG in business
The guide to the EDGE lists several recurring use cases for SMEs and ETIs: internal assistants, legal, technical, customer support, etc.
A first classic use case is that ofgeneral internal assistant. A company provides its teams with an assistant who can summarize reports, suggest draft emails or quickly find an internal policy. Instead of improvising generic rules, the AI will look for the right information in existing HR documents, internal notes, and CRs, and then reformulate them.
Another frequently cited case: thelegal assistant or compliance. For example, a legal department may ask, “What non-competition clauses have we already used with our industrial partners?” ”. The RAG system then goes through the archived contracts, identifies the clauses concerned, compares them and produces a clear summary, with the references of the original contracts.
The RAG is also relevant for technical documentation and maintenance. A technician can ask the system: “How can I replace the X sensor on the Y machine, version 2023?” ”. The AI consults maintenance manuals, past intervention sheets and technical notes, then proposes a structured procedure, with part references and precautions to be respected.
Finally, side customer support and commercial offers, an agent may ask, “What exactly does the Premium offer signed by this customer in 2022 contain? ”. Instead of giving a standard description of the offer, the AI will look for the signed contract and the product sheet from the time, then summarize the customer's rights based on these specific documents.
In all of these cases, the value of the RAG is due to the fact that the answer is both in natural language and anchored in company documents, with the possibility of quickly going back to the source.
6. How RAG helps reduce hallucinations
The RAG does not completely remove the hallucinations, but it reduces them sharply and makes them much more controllable. The model no longer responds in a vacuum: it receives a context composed of excerpts from documents, which guides it to more factual answers. Users can see these snippets, open them, and verify that they have been interpreted correctly.
The guide to the EDGE also highlights the role of the RAG for traceability of information. In a regulatory context marked by RGPD And theAI Act, this traceability is key to justify a recommendation, audit a system or demonstrate that a decision is based on official company documents.
Conclusion: the RAG, the brick that makes AI really useful to your business
La enhanced recovery generation is an answer to a very concrete problem: generative AI models don't know your business and can produce misleading answers if they are not connected to your data.
By combining an engine from retrieving information on your documents and a language model to write answers, the RAG allows you to reduce hallucinations, to anchor the answers in verifiable sources and to save time on all the tasks that involve searching through a large documentary database.
For an SME or an ETI, it is often the best first step in generative AI: no need to retrain a model, possibility of keeping control of your data, and measurable return on investment on very concrete cases (legal, support, technical, HR...). The central idea is simple:
With the RAG, you no longer ask the AI to know everything.
You give them the right documents at the right time and ask them to make the best use of them.
.jpeg)



Ready to start with Delos?
Start now with a 7-day free trial or ask for personalized support.
