
Qu’est-ce que le RAG (génération augmentée de récupération) ?


L’IA générative s’est imposée dans les entreprises pour rédiger des e-mails, résumer des réunions, répondre aux clients ou aider à la veille. Les grands modèles de langage (LLM) comme GPT, Mistral ou Llama savent produire des réponses fluides et souvent pertinentes… mais ils ont un défaut majeur: ils peuvent “halluciner”, c’est-à-dire inventer des informations qui n’existent pas.
Comme le rappelle un article de Oracle, les LLM sont entraînés une fois pour toutes sur de vastes corpus génériques, avec des données parfois périmées et rarement spécifiques à une entreprise donnée. Résultat: ils ne connaissent ni vos contrats, ni vos procédures internes, ni vos produits les plus récents.
De son côté, la Direction générale des entreprises (DGE) explique dans son guide sur la génération augmentée par récupération (2024) que cette limite freine encore l’adoption de l’IA par les PME et ETI: sans prise en compte du contexte métier ni traçabilité des sources, la confiance reste fragile.
La génération augmentée de récupération, ou RAG (Retrieval-Augmented Generation), répond précisément à ce problème. Elle permet à l’IA de consulter vos documents internes en temps réel avant de répondre, plutôt que de se fier uniquement à ce qu’elle a appris lors de son entraînement. L’enjeu est simple: transformer une IA brillante mais générale en un assistant qui connaît réellement votre entreprise.
1. Comment fonctionne une IA générative (et pourquoi elle hallucine)
Un grand modèle de langage fonctionne sur un principe simple: il prédit le prochain mot le plus probable en fonction des mots précédents. Pendant son entraînement, il est exposé à des milliards de phrases, apprend les régularités de la langue, des faits généraux sur le monde et des structures de texte (mails, rapports, articles, etc.). Une fois entraîné, il sait rédiger des contenus cohérents, résumer des documents, expliquer des concepts ou reformuler des messages.
Le problème, pour une entreprise, c’est que ses connaissances sont figées au moment de l’entraînement. Il ne connaît pas vos nouvelles offres, vos politiques internes mises à jour ou les contrats signés l’année dernière s’ils n’étaient pas dans les données d’origine. Par défaut, un LLM ne voit ni vos PDF, ni vos bases de données, ni vos systèmes métier.
Et surtout, quand il ne sait pas, il ne répond pas « je ne sais pas ». Il continue à prédire des mots plausibles, ce qui donne parfois des réponses très convaincantes… mais fausses. C’est ce phénomène qu’on appelle les hallucinations.
Exemple:
Un salarié demande: « Quels sont les droits à la formation dans notre accord d’entreprise ? » Si l’IA n’a jamais vu cet accord, elle va répondre en s’appuyant sur le droit commun ou sur des exemples génériques, sans préciser que ce n’est pas spécifique à votre entreprise.
Face à ça, deux grandes voies existent: réentraîner ou ajuster le modèle sur vos données (ce qui est lourd), ou laisser le modèle consulter vos documents au moment de la question. C’est cette deuxième voie que le RAG met en œuvre.
2. Réentraîner le modèle vs RAG
On pourrait imaginer résoudre le problème des hallucinations en réentraînant régulièrement le modèle sur les documents de l’entreprise. En théorie, plus il voit vos données, plus il les intègre. En pratique, c’est coûteux en temps, en infrastructure et en compétences. Chaque mise à jour significative impose un nouveau cycle de travail, et entre deux entraînements, les connaissances restent figées.
Le réentraînement, c’est comme demander à un étudiant d’apprendre par cœur tout le programme, toutes les annexes et toutes les mises à jour avant l’examen. À chaque changement, il doit réviser tout son cours. Le RAG, lui, ressemble à un examen « open book »: l’étudiant garde ses capacités de raisonnement, mais il a le droit de venir avec un classeur bien organisé et de l’ouvrir pendant l’épreuve. Il ne connaît pas tout par cœur, mais il sait où chercher la bonne information.
Le RAG applique cette logique à l’IA générative. Le modèle conserve son intelligence générale, sa capacité à écrire et à résumer, mais on lui donne en plus un accès contrôlé à vos documents internes et une méthode de recherche pour trouver les passages pertinents avant de répondre. L’article de Oracle résume bien cette approche: la RAG permet d’optimiser les réponses d’un LLM avec des informations ciblées, plus récentes et propres à une entreprise, sans modifier le modèle lui-même.
3. Définition simple du RAG
RAG (Retrieval-Augmented Generation) désigne une famille de techniques qui combinent deux blocs:
- un bloc de récupération d’information, chargé de trouver rapidement dans vos documents les passages les plus pertinents pour une question donnée.
- un bloc de génération, généralement un LLM, qui formule ensuite la réponse en langage naturel à partir de ces passages.
En pratique, cela veut dire que l’IA ne se fie plus seulement à ce qu’elle “a dans la tête”. Elle commence par aller chercher des extraits de vos contrats, de vos procédures ou de vos manuels, puis elle utilise ces extraits pour structurer sa réponse.
Exemple : Plutôt que de demander au modèle standard d’expliquer un contrat client signé en 2023, on lui donne accès à ce contrat au moment de la question. Il lit les clauses pertinentes, puis rédige un résumé adapté à la demande.
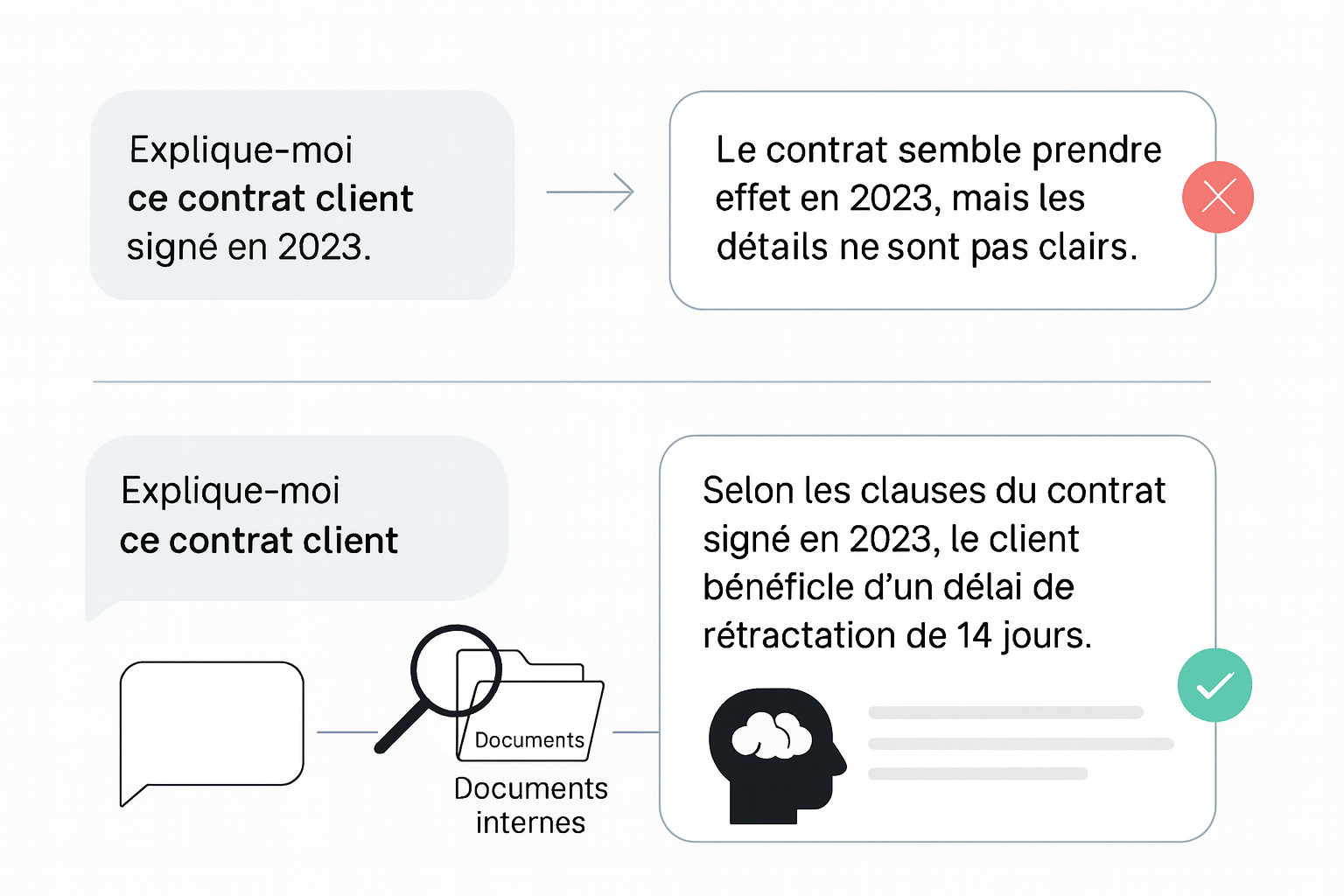
4. Comment fonctionne un système de RAG, concrètement ?
Tout commence par la construction d’une base de connaissances. L’entreprise rassemble les documents utiles: contrats, CGV, documentation technique, procédures internes, comptes-rendus, FAQ, etc. Ces documents sont normalisés dans un format exploitable (souvent texte ou PDF), puis découpés en morceaux plus petits: paragraphes, sections, extraits. Ces segments sont stockés dans une base documentaire.
Vient ensuite une étape clé: la vectorisation. Chaque morceau de texte est transformé en une sorte d’empreinte numérique qui résume son sens. Ces empreintes sont stockées dans une base de données vectorielle, conçue pour que l’IA puisse retrouver rapidement les passages les plus proches d’une question, même si les mots utilisés ne sont pas exactement les mêmes. Des acteurs comme Oracle ou Microsoft insistent sur le rôle central de ces bases dans les systèmes RAG modernes.
Lorsque l’utilisateur pose une question, par exemple: « Quels sont les délais de rétractation prévus dans nos conditions générales de vente B2B ? », le système cherche dans cette base les extraits les plus pertinents (un article des CGV, un avenant, une note juridique) et les envoie au modèle de langage, qui rédige alors une réponse claire à partir de ces éléments.
Un avantage important du RAG est la traçabilité. Chaque extrait étant relié à un document précis, le système peut indiquer d’où vient l’information: nom du fichier, date, section, page. Oracle souligne que cette capacité à remonter à la source permet, en cas d’erreur, de corriger le bon document plutôt que de chercher à l’aveugle.
Exemple:
La réponse affiche: « Délai de rétractation de 14 jours calendaires (CGV 2024, article 4.2). » Juste en dessous, l’interface montre le passage exact du PDF, surligné. Le collaborateur peut vérifier le texte original en une seconde.
5. Cas d’usage concrets du RAG en entreprise
Le guide de la DGE recense plusieurs cas d’usage récurrents pour les PME et ETI: assistants internes, juridique, technique, support client, etc.
Un premier cas d’usage classique est celui de l’assistant interne généraliste. Une entreprise met à disposition de ses équipes un assistant qui sait résumer des comptes-rendus, suggérer des brouillons d’e-mails ou retrouver rapidement une politique interne. Au lieu d’improviser des règles génériques, l’IA va chercher les bonnes informations dans les documents RH, les notes internes et les CR existants, puis les reformule.
Autre cas fréquemment cité: l’assistant juridique ou conformité. Un service juridique peut, par exemple, demander: « Quelles clauses de non-concurrence avons-nous déjà utilisées avec nos partenaires industriels ? ». Le système RAG parcourt alors les contrats archivés, identifie les clauses concernées, les compare et produit une synthèse claire, avec les références des contrats d’origine.
Le RAG est aussi pertinent pour la documentation technique et la maintenance. Un technicien peut interroger le système: « Comment remplacer le capteur X sur la machine Y, version 2023 ? ». L’IA consulte les manuels d’entretien, les fiches d’intervention passées et les notes techniques, puis propose une procédure structurée, avec les références des pièces et les précautions à respecter.
Enfin, côté support client et offres commerciales, un agent peut demander: « Que contient exactement l’offre Premium signée par ce client en 2022 ? ». Plutôt que de donner une description standard de l’offre, l’IA va chercher le contrat signé et la fiche produit de l’époque, puis résume les droits du client en s’appuyant sur ces documents précis.
Dans tous ces cas, la valeur du RAG tient au fait que la réponse est à la fois en langage naturel et ancrée dans les documents de l’entreprise, avec la possibilité de remonter rapidement à la source.
6. Comment le RAG aide à réduire les hallucinations
Le RAG ne supprime pas totalement les hallucinations, mais il les réduit fortement et les rend beaucoup plus contrôlables. Le modèle ne répond plus dans le vide: il reçoit un contexte composé d’extraits de documents, qui le guide vers des réponses plus factuelles. Les utilisateurs peuvent voir ces extraits, les ouvrir et vérifier qu’ils ont été correctement interprétés.
Le guide de la DGE met aussi en avant le rôle du RAG pour la traçabilité de l’information. Dans un contexte réglementaire marqué par le RGPD et l’AI Act, cette traçabilité est clé pour justifier une recommandation, auditer un système ou démontrer qu’une décision repose bien sur des documents officiels de l’entreprise.
Exemple : Un collaborateur RH obtient une réponse sur les congés pour un type de contrat. En un clic, il voit que l’IA a utilisé la convention collective et un accord interne daté de 2023. S’il constate une incohérence, il peut corriger directement la documentation, ce qui améliorera les réponses futures.
Prenons l’exemple sur une plateforme comme Delos, le RAG se traduit par des collections de documents (contrats clients, CGV, procédures internes, documentation produit) reliées à un assistant en langage naturel. L’entreprise importe ses fichiers (PDF, Word, etc.), la plateforme les découpe, les indexe et les vectorise. Lorsqu’un utilisateur pose une question du type: «« Quelles sont les règles de télétravail chez Nova Solutions ? », le système identifie les documents pertinents et génère une réponse synthétique.
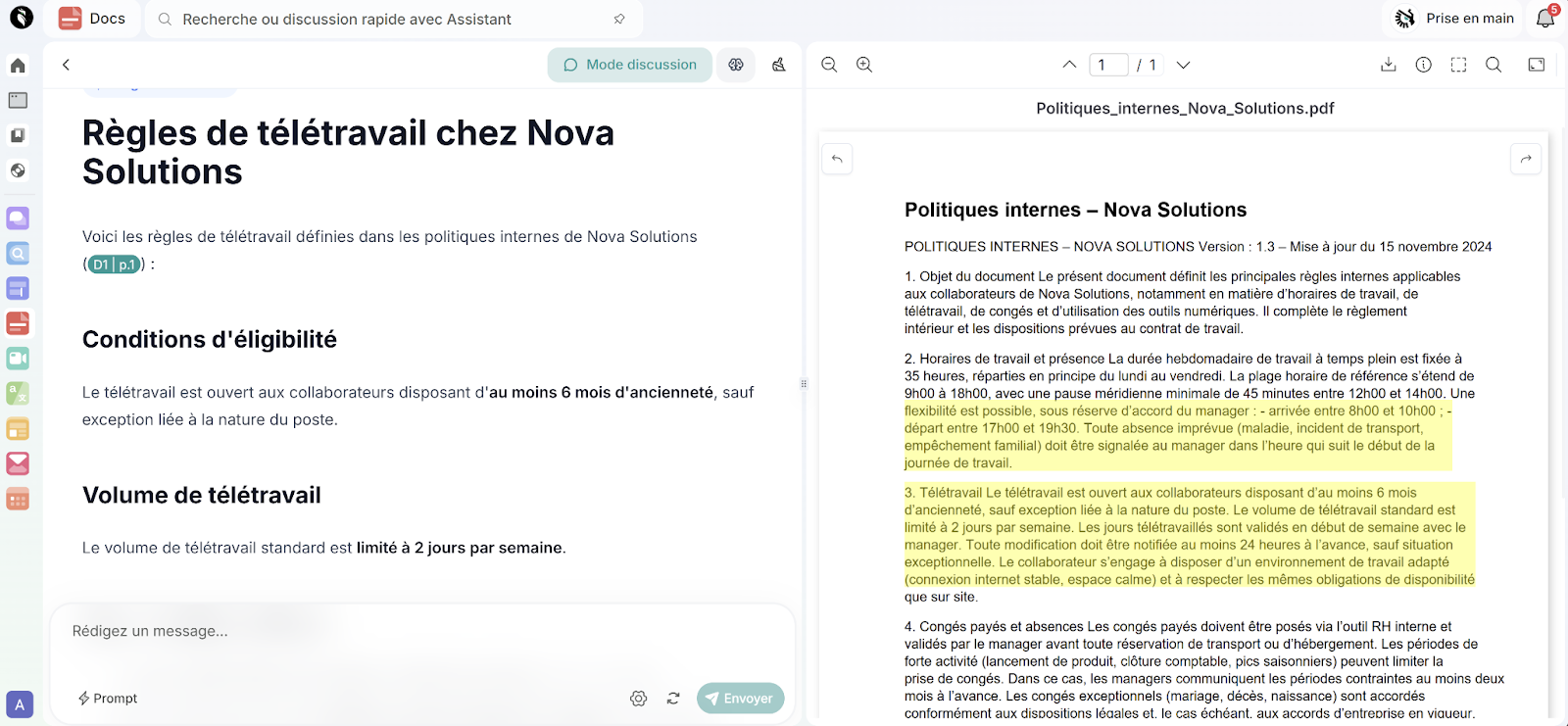
L’interface ne se contente pas d’afficher cette réponse. Elle montre aussi où l’IA a trouvé chaque information: les passages utilisés sont surlignés dans les documents, le nom du fichier apparaît, et l’utilisateur peut ouvrir directement la page exacte du PDF. Dans l’article, une capture d’écran peut illustrer ce fonctionnement: on y voit la collection de documents d’un côté, la réponse de l’IA de l’autre, et les extraits surlignés qui ont servi de base. C’est une démonstration visuelle de ce que permet le RAG: moins de temps passé à chercher, moins de réponses approximatives, et une vérification possible en un coup d’œil.
Conclusion: le RAG, la brique qui rend l’IA vraiment utile à votre métier
La génération augmentée de récupération est une réponse à un problème très concret: les modèles d’IA générative ne connaissent pas votre entreprise et peuvent produire des réponses trompeuses s’ils ne sont pas branchés à vos données.
En combinant un moteur de récupération d’information sur vos documents et un modèle de langage pour rédiger des réponses, le RAG permet de réduire les hallucinations, d’ancrer les réponses dans des sources vérifiables et de gagner du temps sur toutes les tâches qui impliquent de chercher dans une base documentaire volumineuse.
Pour une PME ou une ETI, c’est souvent le meilleur premier pas dans l’IA générative: pas besoin de réentraîner un modèle, possibilité de garder la main sur ses données, et retour sur investissement mesurable sur des cas très concrets (juridique, support, technique, RH…). L’idée centrale est simple:
Avec le RAG, vous ne demandez plus à l’IA de tout savoir.
Vous lui donnez les bons documents au bon moment, et vous lui demandez d’en faire le meilleur usage possible.
Pour tester comment Delos peut vous apporter la solution cliquez ici.
.jpeg)



Prêt à démarrer avec Delos ?
Commencez dès maintenant avec 7 jours offerts ou demandez un accompagnement personnalisé.
